Disclaimer: The views and opinions expressed on this blog are strictly my own and do not reflect those of any past or current employer. The content provided here is for informational purposes only and is not intended to represent the strategies, intentions, or opinions of any organization that I am or have been associated with.
The use of artificial intelligence (AI) permeates many facets of our lives and work. Here I explore the real-world application of AI in the specialist field of transfer pricing (TP) comparable identification process using KPMG’s recent patent (US 11720842 B2 “System and Method for Identifying omparables”).1
Problem statement
The fuel of the benchmarking analysis in TP documentation is comparable data. Transfer pricing professionals face challenges when it comes to accurately identifying comparable companies for benchmarking purposes, each critical to the process’s integrity and outcomes:
- Data Availability: lack of relevant datasets presents challenge for further refinement in the comparable identification process;
- Data Quality: poor data quality can introduce errors and inconsistencies, undermining the credibility and accuracy of the comparability assessment;
- Process Consistency: inconsistent analysis approach may result in unreliable comparisons and difficulties in justifying the selection of comparables;
- Human Error and Bias: similar to inconsistent process, manual comparable searches are time-consuming, labour-tensive, and prone to human error and bias which could compromise the fairness of comparable selected;
- Robust Governance: insufficient or lack of a governance framework may fail to enforce transparency and accountability of a comparable study, raising challenges under regulatory review.
As a result, taxpayers may struggle to justify their chosen comparables before the tax authorities, increasing the risk of disputes and potentially unfavourable outcomes. Tax professionals can address these challenges using a combination of machine learning techniques.
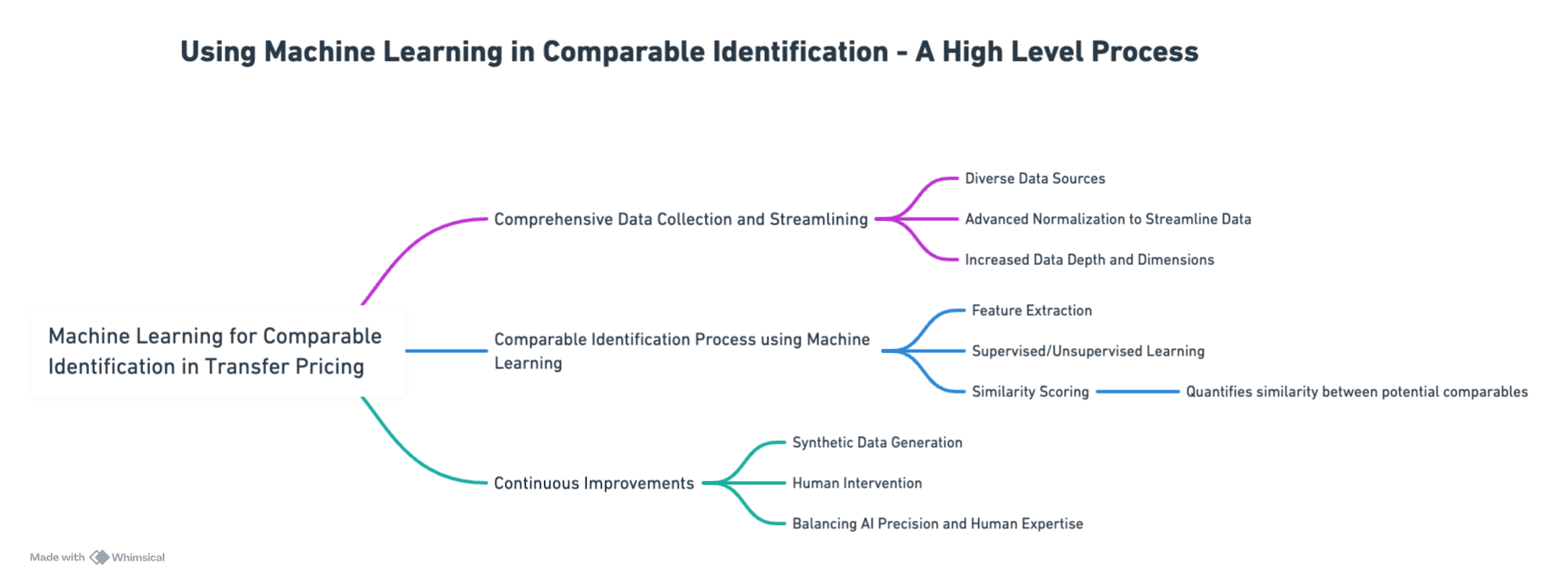
Comprehensive data collection and streamlining
Traditionally, TP analysts use proprietary databases to select a broad set of potential comparables based on the characteristics of the test party. They painstakingly refine this selection to identify the final set of truly comparable data. An AI-enhanced comparable identification system could expand the data collection process, incorporating public information, subscription databases, and potentially proprietary sources. Given the diverse nature of the data sources, advanced normalisation techniques can standardise the information into a uniform format, ensuring consistency and comparability.2 This process includes various tasks, from currency conversion to standardising financial statement formats, and the incorporation of quantitative financial metrics with operational and industry specific descriptors. This is a significant step which increases the depth and dimension of the data available to analyse comparability.
Comparable identification process using machine learning techniques
The main objective of a benchmarking analysis in TP is to identify comparable companies that share similar traits with the test party, ultimately determining an acceptable arm’s length pricing range. Traditionally, this process often involves human judgement, which can result in errors, inconsistencies and biases due to its labour-intensive nature and reliance on manual review of potential comparables.
Machine learning techniques can help alleviate some of the challenges faced in the comparable identification process. For example, feature extraction applies advanced statistical methods such as principal component analysis or natural language textual data extraction to identify essential features (e.g., important financial metrics, relevant industry classifications) from streamlined data collected. These extracted features are then used in machine learning models, making it easier for them to learn patterns in the data.3
Standard machine learning methodologies are employed to determine the acceptance or rejection of comparables. This is based on their alignment with the test party. The process includes supervised learning, where training data are labelled as comparable or non-comparable. It also encompasses model training and selection, cross-validation, hyperparameter optimization (e.g. learning rate and regularisation), model assessment, and ongoing enhancements.
Continuous improvements
“It is remarkably easy to incur massive ongoing maintenance costs at the system level when applying machine learning.” - D.Sculley et al, Google Inc4
The implementation of a machine learning system requires continuous learning and improvement to ensure its relevance and accuracy. The KPMG patent details methodologies like the use of synthetic data generation and mandatory human intervention to refine and enhance the AI model’s learning curve. Synthetic data helps address the gaps in real data and enhances the model’s exposure to different scenarios, which in turn improves the system’s predictive accuracy and robustness. On the other hand, a human intervention framework ensures that the models’ learning aligns with human expertise and safeguards the model reliability.
The use of synthetic data requires careful validation to ensure that the generated data accurately reflect real-world scenarios, paying attention to avoid introducing biases or misguiding the model training. At the same time, human intervention requires careful calibration to maintain consistency and objectivity in the analysis, balancing efficiency and avoiding potential issues such as over-reliance on one method or another.5
Conclusion: embracing change for future-proof transfer pricing
Integrating AI into the nuanced field of comparable identification in TP can yield transformative gains for tax professionals in terms of efficiency, eliminating inconsistencies in benchmarking analysis, and reducing the risk of disputes. It is therefore important for tax professionals to both embrace the change whilst remaining vigilant about data integrity, model transparency, and the ongoing human intervention for model reliability and explainability.
Notes
Galginaitis et al, System and methods for identifying comparables, KPMG LLP patent number 11720842, 8 Aug 2023 ↩︎
Many reliable open-source packages are available when it comes to data normalisation, including Python based Pandas, scikit-learn, R based dplyr and tidyr. ↩︎
Python based scikit-learn and spaCy are two reliable and comprehensive open-source packages that offer robust feature extraction solutions including Principal Component Analysis and entity relationship extracton respectively. ↩︎
D. Sculley, G. Holt, D. Golovin, E. Davydov, T. Phillips, D. Ebner, V. Chaudhary, M. Young, J.-F. Crespo, and D. Dennison, “Hidden technical debt in Machine Learning systems,” in Neural Information Processing Systems, vol. 2, MIT Press, 2015 ↩︎
One resource to learn more about the use of synthetic data in machine learning models can be found at https://sdv.dev/ ↩︎